Key takeaways
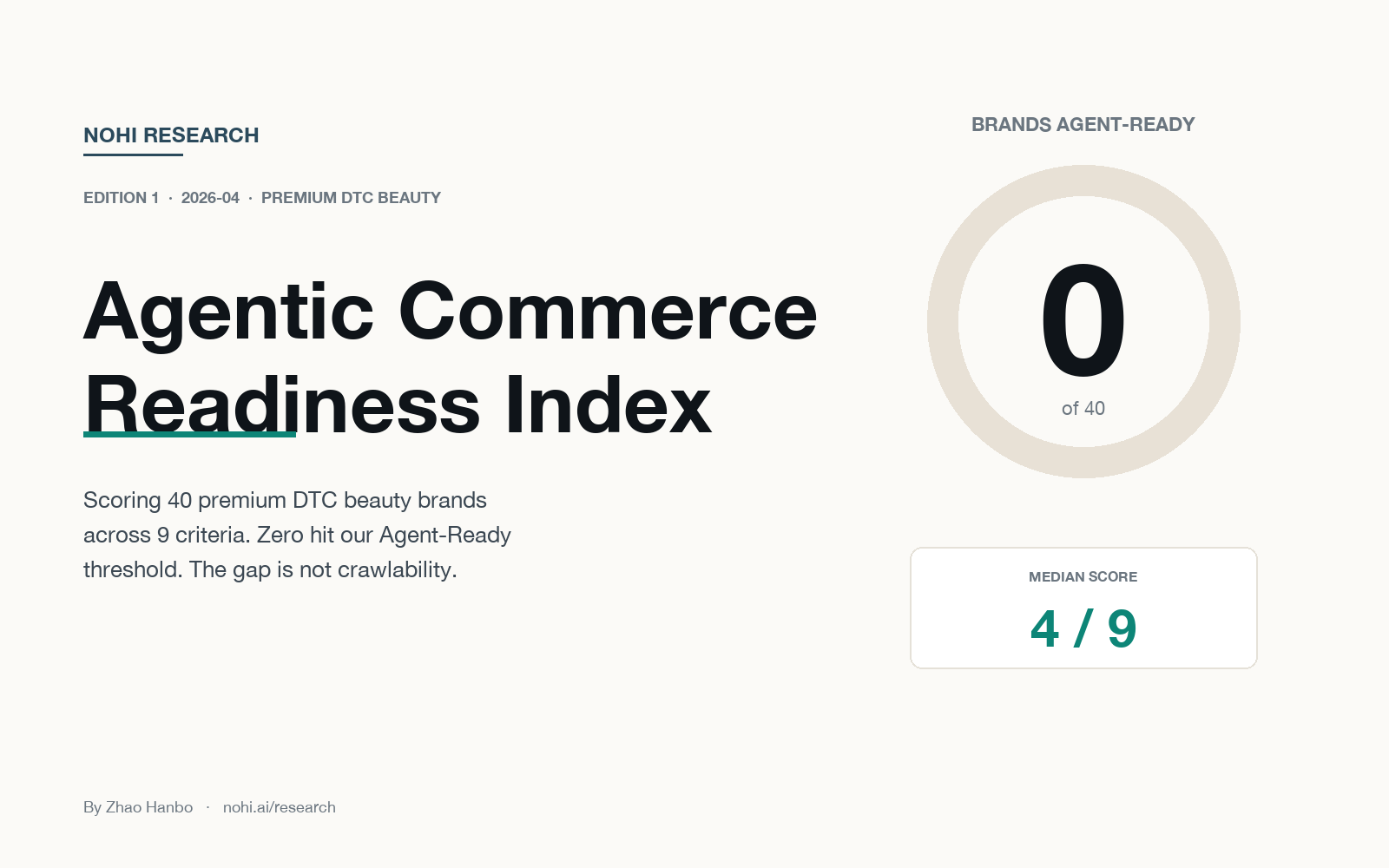
- We scored 40 premium DTC beauty brands on 9 criteria across crawlability, structured data, and content quality. Zero hit our "Agent-Ready" threshold of 7 out of 9.
- The median score was 4. The top 7 brands tied at 6/9: Rare Beauty, Phlur, Milk Makeup, Ceremonia, OSEA Malibu, Krave Beauty, and Hero Cosmetics.
- The bottleneck is not crawlability (92% pass), it's content. Only 12.5% of PDPs had descriptions that answered the comparison questions AI assistants need to quote. We're calling this pattern The Content Cliff.
- Prestige does not predict readiness. Hero Cosmetics (a mass-market patch brand) outscored Drunk Elephant, Ilia Beauty, and Westman Atelier. Marketing budget is not a proxy for structured-data hygiene.
- For merchants at 3/9: five-minute fixes to Product and Review schema can move you to 6/9 without new content.
Why this study exists
Agentic commerce is projected to drive a material share of online retail revenue by 2030, and every merchant conversation about it starts with the same question: "Is our site ready?" Until now, nobody has scored it.
This Index is our attempt to answer that concretely for premium DTC beauty, the category where Shopify-native independent brands dominate, AOVs sit in the $25-$150 range, and AI assistants have active merchant-recommendation behavior today.
We intend to publish one edition roughly every month, each covering a different category. Year-over-year reruns of Edition 1 become the tentpole moments, so methodology has to stay stable enough to support "2027 vs 2026" comparisons.
The 9-criterion rubric
The full methodology is published so it can be replicated or disputed. Criteria are grouped into three areas:
Area 1, Crawlability and access (can AI agents reach your content?)
- C1.
robots.txtallows the major AI crawlers: GPTBot, PerplexityBot, ClaudeBot, Google-Extended, Amazonbot, CCBot, FacebookBot (pass = at least 4 allowed) - C2. Product pages render server-side, core product data (title, price, description) present in raw HTML without JS execution, verified across 3 random PDPs
- C3. Sitemap.xml is current, at least one
<lastmod>within 90 days
Area 2, Structured data (can AI agents parse what they find?)
- C4.
Productschema on PDPs withname,image,brand,offers(price + availability), and at least one ofgtin/mpn/sku, verified on same 3 PDPs - C5.
RevieworAggregateRatingschema with actual review counts (not placeholders) - C6.
FAQPageorHowToschema on at least one help / about / how-to-use page - C7.
Organizationschema withname,url, and at least 2sameAsentries (social profiles, Wikidata, etc.)
Area 3, Content quality (can AI agents quote you?)
- C8. PDP titles include a specific use case, target audience, or differentiator (not just brand + product name), LLM evaluation across 5 sampled PDPs
- C9. Descriptions address at least 3 of: target skin/hair type, comparison to alternatives, ingredient rationale, sizing/volume reasoning, usage instructions, what the product is NOT for, LLM evaluation across 5 sampled PDPs
- C10. Content uniqueness, deferred to Edition 2+; Edition 1 max score is therefore 9
Scoring is binary (0 or 1) per criterion. Tie-break ranking goes Area 3 > Area 2 > Area 1 > alphabetical, because content quality is hardest to fake and most predictive of real agent recommendation behavior.
Sample construction
We built a target sample of 50 brands using four sources: Storeleads top Shopify beauty, Shopify Editions features, a curated premium DTC catalog (Sephora Clean, Credo Beauty, Beauty Independent coverage), and BuiltWith-confirmed premium Shopify fashion-beauty sites. The list spans skincare, makeup, haircare, fragrance, body, and beauty-wellness bridge.
Of those 50, 40 made the final ranking:
- 6 could not be reliably fetched (Tata Harper, Youth To The People, Violette_FR, Ami Colé, Pinch of Color, Adwoa Beauty), a mix of bot-protection, DNS issues, and a single data-processing bug on our end
- 4 had migrated off Shopify since the time our sourcing data was generated (Topicals, Drunk Elephant, Biossance, Item Beauty), all are now on Salesforce Commerce Cloud, custom stacks, or acquired-and-migrated
Both exclusion groups are themselves a small finding: about 20% of "known premium DTC beauty on Shopify" is actually either unreachable by automated clients or no longer on Shopify. AI assistants face the same visibility issues we faced as scorers.
Distribution of scores
Across the 40 ranked brands:
- Median score: 4 / 9
- Mean score: 4.03 / 9
- Highest score: 6 / 9 (seven-way tie)
- Number scoring 7+ (our "Agent-Ready" tier): 0
- Number scoring 2 or lower: 4
Full distribution:
| Score | Brand count |
|---|---|
| 7+ | 0 |
| 6 | 7 |
| 5 | 9 |
| 4 | 6 |
| 3 | 14 |
| 2 | 4 |
The Content Cliff
Pass rates by criterion, sorted ascending, tell the structural story:
| # | Criterion | Area | Pass rate |
|---|---|---|---|
| C9 | Descriptions answer comparison questions | Content | 12.5% |
| C6 | FAQPage / HowTo schema present | Structure | 12.5% |
| C5 | Review / AggregateRating schema | Structure | 30.0% |
| C4 | Product schema complete | Structure | 37.5% |
| C8 | PDP titles with differentiator | Content | 40.0% |
| C3 | Sitemap current (90d) | Crawl | 47.5% |
| C7 | Organization schema | Structure | 57.5% |
| C2 | PDP server-side render | Crawl | 72.5% |
| C1 | AI crawler access | Crawl | 92.5% |
The pattern is unambiguous . Crawlability, the infrastructure layer that a platform handles for you, passes at 47-92%. Structured data, the layer that requires a widget install and some configuration, drops to 30-57%. Content quality, the layer that requires actual editorial work, collapses to 12-40%.
The further a criterion sits from "something a plugin can do for you" and closer to "something a human has to write", the worse premium DTC beauty scores on it.
We are calling this pattern The Content Cliff, and we expect it to be the consistent finding across every category this Index covers. The infrastructure for agentic commerce is already in place. The content to feed it is not.
Top 7, tied at 6/9
No brand in this sample earned an Agent-Ready rating. The top tier is a seven-way tie.
| Rank | Brand | A1 | A2 | A3 | Notable |
|---|---|---|---|---|---|
| 1 | Rare Beauty | 2 | 3 | 1 | Celeb-founded (Selena Gomez); complete Product + Review + Organization schema |
| 2 | Phlur | 2 | 3 | 1 | Clean fragrance; Missing Person viral; full structured-data stack |
| 3 | Milk Makeup | 3 | 2 | 1 | Long-running brand; strong crawlability and PDP structure |
| 4 | Ceremonia | 3 | 2 | 1 | Babba Rivera-founded Latinx haircare; strong full-stack |
| 5 | OSEA Malibu | 3 | 2 | 1 | Seaweed-based clean skincare; long-form PDP content |
| 6 | Krave Beauty | 3 | 3 | 0 | Liah Yoo K-beauty; best-in-class structured data but content still generic |
| 7 | Hero Cosmetics | 3 | 3 | 0 | Mighty Patch parent; budget tier, best-in-class structured data |
Ties are broken first by Area 3 (content), then Area 2 (structure), then Area 1 (crawl), then alphabetically.
The surprise: Hero Cosmetics outscored Drunk Elephant (2/9), Ilia Beauty (2/9), and Westman Atelier (3/9). Mighty Patch, a $6.99 acne patch brand, ships better structured data than three beauty-editor-favorite premium lines. Marketing budget is not structured-data hygiene.
The review-schema loss
30% of brands have Review / AggregateRating schema despite an estimated 95%+ of the sample displaying reviews on their sites. The reviews exist. The structured data does not. This is almost always a widget-vendor toggle that hasn't been flipped, brands are paying $500-$5,000/month for Yotpo, Judge.me, Okendo, or similar, while the vendor's structured-data output stays disabled.
For any brand in the 3-5 range, enabling review schema is typically the fastest +1 available.
Who should do what
For merchants scoring 3/9 or lower : the fastest wins are in structured data, not content. Turn on Product and Review schema output in your review and e-commerce plugins (often one checkbox). Add basic Organization schema to the homepage. These three moves alone will typically get you to 5/9 in an afternoon.
For merchants scoring 4-5/9 : the content layer is now the bottleneck. Audit a sample of 20 PDP descriptions against the C9 rubric, do they answer comparison questions, specify use cases, and name what the product is *not* for? This is where editorial work actually moves the needle, and where AI assistants actually get quotable material.
For merchants scoring 6/9 : you're in the top tier of premium DTC beauty, but there is no top tier yet, everyone is in the middle. The missing 1-3 criteria are usually FAQPage schema on help content, or description-level content quality. Both are genuine editorial projects, not plugin toggles.
For investors and operators in the agentic commerce stack : the implication is that tool vendors who quietly enable full schema output in their product (without adding per-merchant friction) are going to become mandatory infrastructure faster than most expect. The brands aren't going to write the schema by hand.
Methodology disclosures and caveats
- Single point-in-time scoring: brands may have fixed specific gaps between our test date (2026-04-19) and this publication. We will rescore on request when significant structured-data changes are made.
- Sample selection focused on US-facing Shopify premium beauty. We deliberately excluded luxury ($150+ AOV), drugstore mass-market, subscription-only, and non-Shopify commerce platforms.
- PDP sampling is random: three to five product pages are selected from each brand's
/products.jsonfeed or sitemap, which means a brand could pass some criteria on an unlucky sample. Running the scorer multiple times would smooth this, we did not do that for Edition 1 to keep methodology reproducible. - C10 deferred: content uniqueness requires Originality.ai or Copyscape integration, which we did not ship for Edition 1. Max score is therefore 9. Edition 2 will add C10 and max will be 10.
- LLM evaluator details: Criteria C8 and C9 used
gpt-5.4-miniat low reasoning effort. Full evaluation prompts and extracted PDP titles/descriptions are in the reproducibility bundle.
What Edition 2 will cover
The next edition is under consideration. Likely candidates: Premium DTC Menswear, Premium DTC Womenswear, Home and Lifestyle, Wellness and Supplements, or Fragrance. Priority will be driven by audience response to this Edition and where Nohi's own merchant conversations are loudest.
If you'd like your category scored first, reply in the comments of our LinkedIn announcement or DM directly. If you'd like your own brand personally rated, including a detailed gap analysis and specific fixes, the same channels apply.
Download the full dataset
All underlying data is published to a public GitHub repository under CC BY 4.0. Free to cite, reanalyze, and build on with attribution.
- Raw data repo: github.com/zhao-hanbo/readiness-index-2026-beauty
- Interactive dashboard + per-brand audits: zhao-hanbo.github.io/readiness-index-2026-beauty
- Full scores for all 40 ranked brands (CSV): scores.csv
- Per-criterion evaluation details (JSONL, one object per brand): scores.details.jsonl
- Methodology in full: methodology.md
- Top 10 notable findings (including the Content Cliff): notable-findings.md